1、冒泡排序(Bubble Sort):
冒泡排序是一种简单的排序算法。它重复地遍历要排序的列表,比较相邻的两个元素,并交换它们的位置,直到列表排序完成为止。每次遍历都会将最大的元素移动到列表的末尾。冒泡排序算法的时间复杂度为O(n^2)。
2、插入排序(Insertion Sort):
插入排序通过构建一个有序序列,依次将列表中的元素插入到适当的位置来实现排序。从第一个元素开始,它会与已排序序列中的元素进行比较,并将其插入到正确的位置。插入排序算法的时间复杂度为O(n^2)。
3、选择排序(Selection Sort):
选择排序是一种简单直观的排序算法。它将列表分为已排序和未排序两部分。每次选择未排序部分的最小元素,并将其放到已排序部分的末尾,逐步构建有序序列。选择排序算法的时间复杂度为O(n^2)。
4、快速排序(Quick Sort):
快速排序是一种高效的排序算法,在大多数情况下都比冒泡排序、插入排序和选择排序更快。它使用分治法的思想,通过选择一个基准元素,将列表分成两个子列表,并对每个子列表递归地进行排序。快速排序算法的时间复杂度为O(nlogn)。
5、归并排序(Merge Sort):
归并排序是一种稳定的排序算法。它将列表分成较小的子列表,对每个子列表进行排序,然后再将子列表合并成较大的有序列表,直到整个列表排序完成。归并排序算法的时间复杂度为O(nlogn)。
6、堆排序(Heap Sort):
堆排序是一种利用堆数据结构的排序算法。它通过构建一个二叉堆,在堆的性质下进行排序。堆排序分为两个阶段:建堆和排序。建堆阶段将无序列表转换为堆,排序阶段将堆的根节点依次取出,并调整堆,完成排序。堆排序算法的时间复杂度为O(nlogn)。
以上所述排序算法均以升序为例,也可以针对降序进行相应的修改。这些排序算法可以根据具体的需求选择使用,每种算法都有自己的优点和缺点,需要根据数据规模和性能要求进行选择。
C# 常见排序算法的完整代码示例:
1、冒泡排序(Bubble Sort):
public void BubbleSort(int[] arr)
{
int n = arr.Length;
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
// 交换元素
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
2、插入排序(Insertion Sort):
public void InsertionSort(int[] arr)
{
int n = arr.Length;
for (int i = 1; i < n; i++)
{
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key)
{
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
3、选择排序(Selection Sort):
public void SelectionSort(int[] arr)
{
int n = arr.Length;
for (int i = 0; i < n - 1; i++)
{
int minIdx = i;
for (int j = i + 1; j < n; j++)
{
if (arr[j] < arr[minIdx])
{
minIdx = j;
}
}
int temp = arr[minIdx];
arr[minIdx] = arr[i];
arr[i] = temp;
}
}
4、快速排序(Quick Sort):
public void QuickSort(int[] arr, int low, int high)
{
if (low < high)
{
int pivot = Partition(arr, low, high);
QuickSort(arr, low, pivot - 1);
QuickSort(arr, pivot + 1, high);
}
}
private int Partition(int[] arr, int low, int high)
{
int pivot = arr[high];
int i = low - 1;
for (int j = low; j < high; j++)
{
if (arr[j] < pivot)
{
i++;
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
int temp2 = arr[i + 1];
arr[i + 1] = arr[high];
arr[high] = temp2;
return i + 1;
}
5、归并排序(Merge Sort):
public void MergeSort(int[] arr, int low, int high)
{
if (low < high)
{
int mid = (low + high) / 2;
MergeSort(arr, low, mid);
MergeSort(arr, mid + 1, high);
Merge(arr, low, mid, high);
}
}
private void Merge(int[] arr, int low, int mid, int high)
{
int n1 = mid - low + 1;
int n2 = high - mid;
int[] L = new int[n1];
int[] R = new int[n2];
for (int i = 0; i < n1; ++i)
L[i] = arr[low + i];
for (int j = 0; j < n2; ++j)
R[j] = arr[mid + 1 + j];
int k = low;
int p = 0, q = 0;
while (p < n1 && q < n2)
{
if (L[p] <= R[q])
{
arr[k] = L[p];
p++;
}
else
{
arr[k] = R[q];
q++;
}
k++;
}
while (p < n1)
{
arr[k] = L[p];
p++;
k++;
}
while (q < n2)
{
arr[k] = R[q];
q++;
k++;
}
}
6、堆排序(Heap Sort):
public void HeapSort(int[] arr)
{
int n = arr.Length;
for (int i = n / 2 - 1; i >= 0; i--)
{
Heapify(arr, n, i);
}
for (int i = n - 1; i >= 0; i--)
{
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
Heapify(arr, i, 0);
}
}
private void Heapify(int[] arr, int n, int i)
{
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest])
{
largest = left;
}
if (right < n && arr[right] > arr[largest])
{
largest = right;
}
if (largest != i)
{
int temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
Heapify(arr, n, largest);
}
}
以上是常见的排序算法的C#代码示例。你可以根据需要使用这些算法来对数组进行排序。
相关文章
C语言中strstr函数的使用!


C# 如何实现一个事件总线
C# winfrom中excel文件导入导出

C#中的浅度和深度复制(C#如何复制一个对象)

C#之linq和lamda表达式GroupBy分组拼接字符串
为什么Java中的String类被设计为final类?
【.NET Core】深入理解任务并行库 (TPL)

FluentValidation在C# WPF中的应用

大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解

【.NET Core】Lazy<T> 实现延迟加载详解
C# Onnx Chinese CLIP 通过一句话从图库中搜出来符合要求的图片

【C#】.net core 6.0 依赖注入生命周期
C++归并排序详解以及代码实现
高并发场景下如何实现系统限流?

【C#】.net core 6.0 通过依赖注入注册和使用上下文服务
C#动态生成带参数的小程序二维码


多旋翼无人机组合导航系统-多源信息融合算法(Matlab代码实现)

【WSN】基于蚁群算法的WSN路由协议(最短路径)消耗节点能量研究(Matlab代码实现)
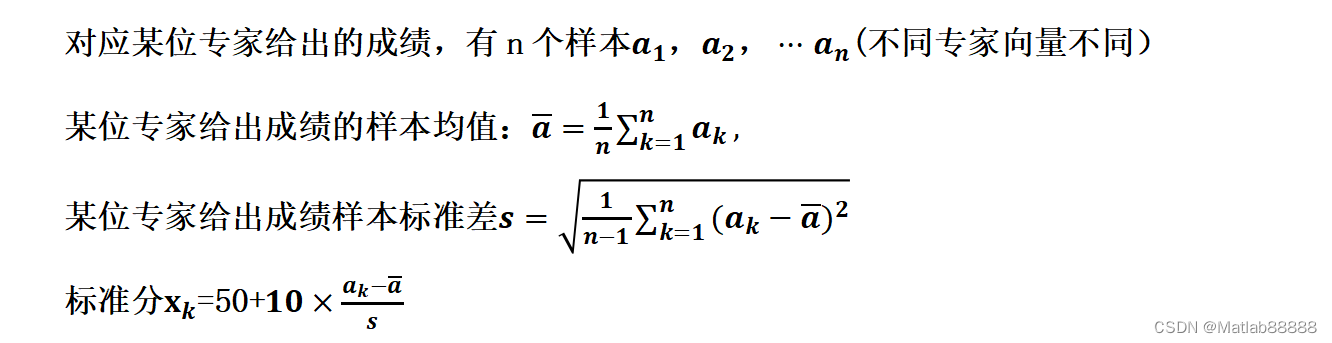
【 2023华为杯C题】大规模创新类竞赛评审方案研究(思路、代码......)
